第19届国际计算机视觉会议(International Conference on Computer Vision (ICCV) 2023)于2023年7月14日公布了论文接收情况,澳门科技大学创新工程学院计算机科学与工程学院的多篇论文获接收。ICCV是最顶尖的人工智能与计算机视觉方向的国际会议之一。
创新工程学院计算机科学与工程学院梁延研副教授、万军特聘副教授、张渡讲座教授团队今年被ICCV2023接收了三篇论文,第一作者分别为创新工程学院计算机科学与工程学院研究生朱震威、杨俪莹及周本加,通讯作者分别为梁延研副教授和万军副教授。这是近年来澳科大在计算机科学和人工智能相关学科方面对培养人才和科学研究的重要成果。
这是继在多个人工智能国际顶尖会议(如:Association for the Advancement of Artificial Intelligence (AAAI) Conference on Artificial Intelligence, International Joint Conference on Artificial Intelligence (IJCAI), IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR))上发表论文后,澳科大科研团队在人工智能国际顶尖会议上取得的又一新突破,也是澳科大作为第一单位首次于ICCV发表研究论文。上述会议均得到中国计算机学会推荐并评级为人工智能领域的A类会议(注:A类为最高级别,中国计算机学会对该类别的定义是国际上极少数的顶级刊物和会议,鼓励我国学者去突破)。
研究论文得到国家科技部-澳门科技发展基金联合项目“通用视觉模型关键技术研究”(0070/2020/AMJ)、澳门科技发展基金面上项目“增强现实中的关键技术研究”(0004/2020/A1)和广东省重点领域研发计划项目“虚拟现实核心引擎关键技术平台研发及产业化”(2019B010148001)资助。
三篇论文题目和摘要如下:
1. UMIFormer: Mining the Correlations between Similar Tokens for Multi-View 3D Reconstruction.
近年来,Vision Transformer结合空间-时间解耦的特征提取方法在视频处理任务上取得突破。同样作为应对多张图像输入的问题,多视角3D重建任务却无法直接继承这种方式。这是因为无序的视角之间关联性完全不确定,并没有类似于视频数据中时序相关性的先验条件可用。为了解决这样的问题,我们提出了UMIFormer——一个全新的transformer网络用于处理无序的多张图像输入。该结构利用Transformer块做解耦的视图内编码,并依赖我们设计的token校正块,挖掘不同视角之间相似tokens的关联性,以实现解耦的视角间编码。之后,再次依据相似性,将从各个视角分支获取的tokens压缩为固定大小的紧致表示,同时保留丰富的信息用于重建。在ShapeNet数据集上,我们验证了所提出的解耦学习方式确实适用于处理无序的多张图像。同时,我们的模型也大幅优于现有的最好方法。
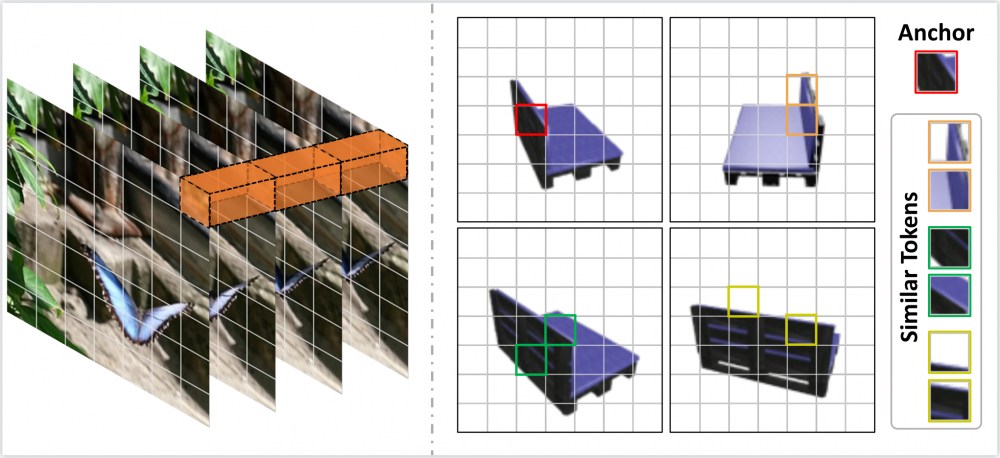
多视角输入的相似性Token示意图,挖掘相似的Token有利于将相似信息形成关联
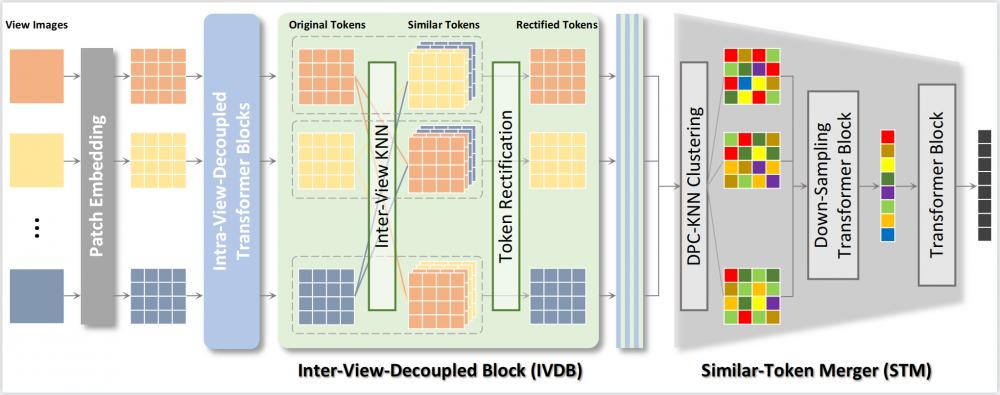
所提出的方法架构
2. Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining.
这篇文章中我们提出了一种不需要依赖Gloss 标注信息(gloss-free)的手语翻译(SLT)方法: GFSLT-VLP。Sign Language Gloss 信息的标注需要花费巨大的人力物力成本,而且还需要专门的语言专家进行细粒度标注。这导致当数据规模比较大时,这种标注浪费资源且工程巨大。本文提出的Gloss-free SLT方法首次实现了在完全不需要依赖Gloss标注的情境下,显著缩小了与Gloss-based 方法之间的性能差距。整个方法包含两个关键步骤:(i)将多模态预训练领域的视文对比学习范式(CLIP)和NLP领域的掩码自监督学习范式(MSL)结合到一起预训练视觉编码器(Visual Encoder)和文本解码器(Text Decoder)。(ii)构建一个端到端的SLT模型架构,它具有类似编码器-解码器的结构,并继承了第一阶段学习到的视-文知识,从而有效地捕获到语言知识引导的手势特征。这些新颖设计的无缝结合形成了鲁棒的手语表示,并显著提高了Gloss-free手语翻译的性能。
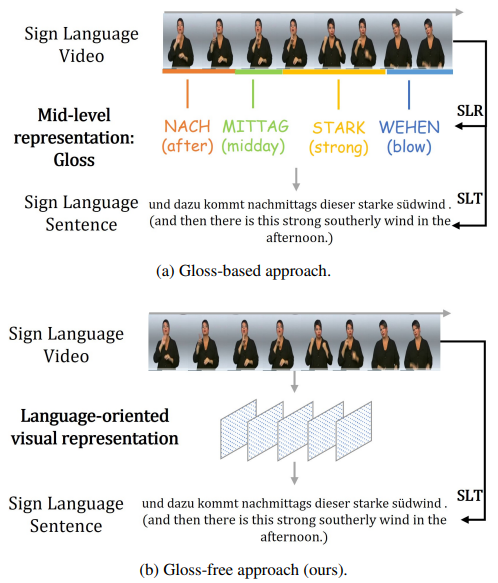
两种不同的SLT方法。 (a)使用Gloss序列作为中间表示,例如,sign2gloss2text(直接),Sign2Text(间接);(b)在整个训练/推理过程中不使用Gloss信息
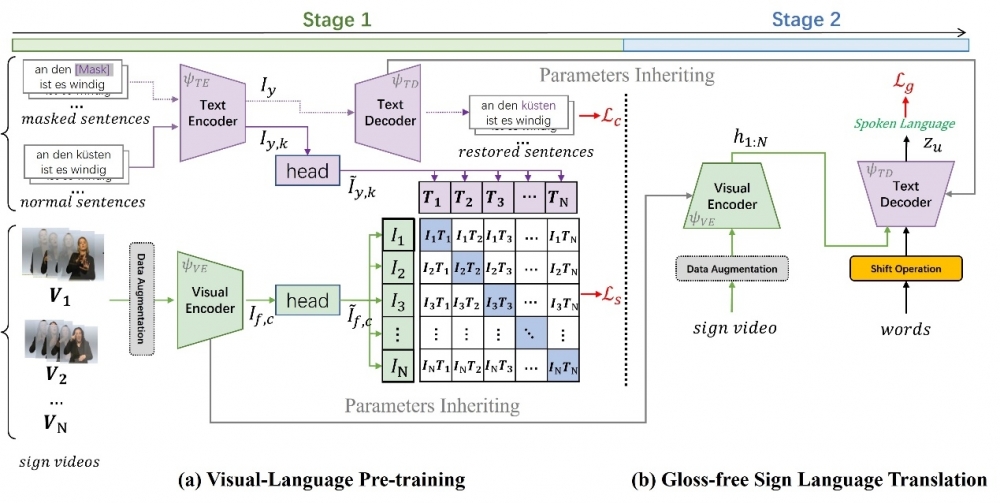
所提出的方法架构。(a)第一阶段进行视-文预训练; (b)继承视-文知识并进行端到端的手语翻译任务
3. Long-Range Grouping Transformer for Multi-View 3D Reconstruction.
目前,Transformer在许多计算机视觉任务中都表现出了优越的性能。在遵循这一范式的多视图三维重建算法中,当面对大量的视图输入时,自注意力需要处理包含大量信息的复杂图像令牌。信息内容的爆炸导致模型学习的难度极大。为了缓解这个问题,最近的方法压缩了表示每个视图的令牌,或者放弃计算不同视图令牌之间的注意力。显然,它们会对性能产生负面的影响。因此,我们提出了基于分而治之原则的长距离分组注意力(LGA)。来自所有视图的令牌都会被分组,以进行单独的注意力操作。每个组中的令牌从所有视图中采样,并且可以为当前视图提供宏观表示。不同组间的多样性确保了特征学习的丰富性。我们通过使用LGA连接视图间特征,并使用标准的自注意力层提取视图内特征,提出一种高效的编码器。 此外,我们设计出一个新颖的渐进式上采样解码器,用于生成具有相对高分辨率的体素。基于以上内容,我们最终构建出一种基于Transformer的网络,命名为LRGT。在ShapeNet数据集上的结果证明LRGT在多视图三维重建任务中达到了卓越的性能。
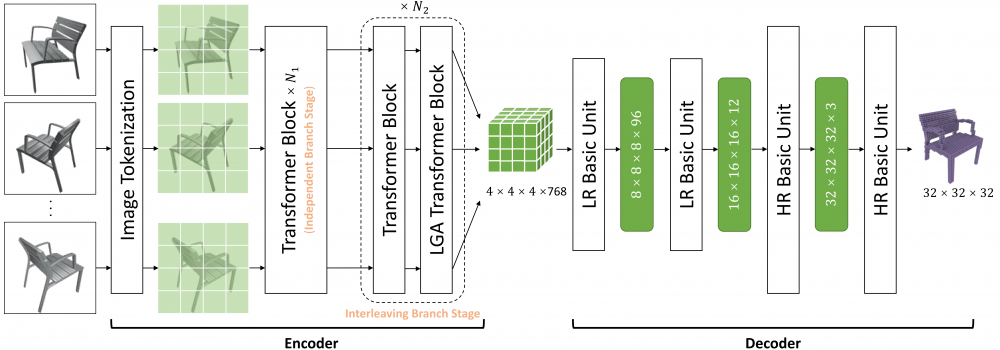
提出的方法架构




