The 19th International Conference on Computer Vision (ICCV 2023) announced its paper acceptance status on July 14th, with multiple papers from the School of Computer Science and Engineering being accepted. ICCV is the premier international computer vision event comprising the main conference and several co-located workshops and tutorials, alongside The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), both organized by IEEE/CVF. ICCV takes place biennially, and this year's event is scheduled to be held from October 2nd to 6th in Paris, France.
Associate Professor Liang Yanyan, Distinguished Associate Professor Wan Jun, and Chair Professor Zhang Du, from the School of Computer Science and Engineering, Faculty of Innovation Engineering, submitted a total of seven papers to ICCV 2023, out of which three were accepted. The first authors of these three papers are Zhu Zhenwei (second-year Ph.D. student), Yang Liying (second-year master's student) and Zhou Benjia (second-year Ph.D. student), and Associate Professor Liang Yanyan and Associate Professor Wan Jun are the corresponding authors respectively. Three students, all of them first authors, have achieved significant milestones at the Macau University of Science and Technology (MUST). Zhu Zhenwei, a student cultivated by the university, holds a Bachelor degree of Science in Software Engineering from the 2015 cohort, a Master's degree of Science in Information Technology from the 2019 cohort, and is currently pursuing a Ph.D. in Artificial Intelligence from the 2021 cohort. Likewise, Yang Liying, also nurtured by MUST, obtained a Bachelor degree of Science in Electronic Information Technology in 2017 and is currently pursuing a Master's degree of Applied Mathematics and Data Science from the 2021 cohort. She is about to embark on her Ph.D. journey in Computer Technology and its Applications in the upcoming 2023 cohort. Completing this trio of talented students is Zhou Benjia, who obtained a Master's degree of Science in Information Technology from the 2019 cohort and is currently pursuing a Ph.D. in Artificial Intelligence from the 2021 cohort. These achievements showcase the Macau University of Science and Technology commitment to nurturing talents and conducting scientific research in the fields of information technology and computer science in recent years.
This marks a significant achievement for the research team in Faculty of Innovation Engineering, following previous paper publications at several other Tier 1 international AI conferences, including AAAI 2021, IJCAI 2022, CVPR 2022 and AAAI 2023. It also represents the first time that the Macau University of Science and Technology has presented research papers at ICCV as the primary affiliation. Above-mentioned conferences are highly recommended and rated as the Class A conferences in AI area by China Computer Federation (CCF). (Note: Class A represents the highest level, as defined by CCF, indicating that these conferences are among the very few top-tier international journals and conferences. This encourages Chinese scholars to excel and make breakthroughs in their respective fields). These researches are supported by MOST-FDCT project “Building Incrementally Improved General Visual Models for AutoML: a STEP Perpetual Refinement Approach”(0070/2020/AMJ), FDCT project “Key Technologies for Augmented Reality” (0004/2020/A1), and Guangdong Provincial Key R&D Programme “Research and Industrialization of Key Technology Platform for Virtual Reality Core Engine” (2019B010148001).
The titles and abstracts of the three accepted papers are as follows:
1. In recent years, many video tasks have achieved breakthroughs by utilizing the vision transformer and establishing spatial-temporal decoupling for feature extraction. Although multi-view 3D reconstruction also faces multiple images as input, it cannot immediately inherit their success due to completely ambiguous associations between unordered views. There is not usable prior relationship, which is similar to the temporally-coherence property in a video. To solve this problem, we propose a novel transformer network for Unordered Multiple Images (UMIFormer). It exploits transformer blocks for decoupled intra-view encoding and designed blocks for token rectification that mine the correlation between similar tokens from different views to achieve decoupled inter-view encoding. Afterward, all tokens acquired from various branches are compressed into a fixed-size compact representation while preserving rich information for reconstruction by leveraging the similarities between tokens. We empirically demonstrate on ShapeNet and confirm that our decoupled learning method is adaptable for unordered multiple images. Meanwhile, the experiments also verify our model outperforms existing SOTA methods by a large margin.
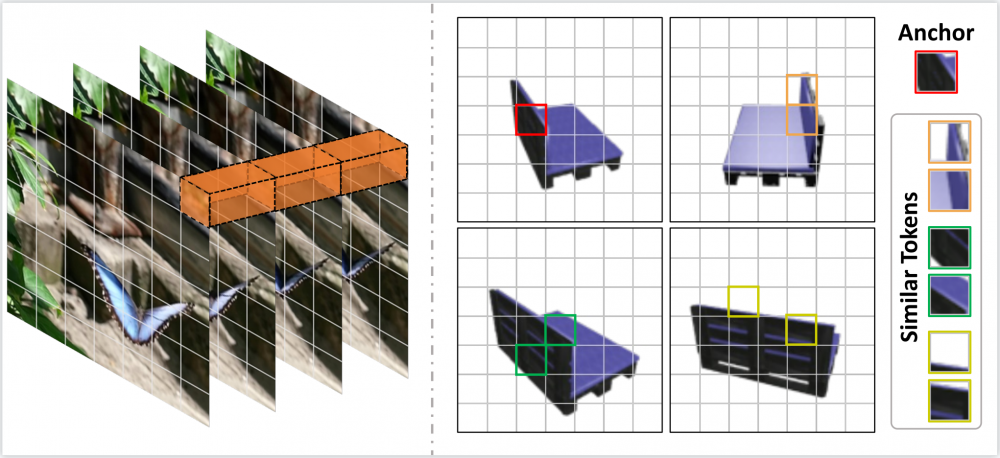
Figure 1. Conceptual Diagram of Similarity Tokens from Multi-view Inputs, mining similar tokens facilitates establishing connections between related information.
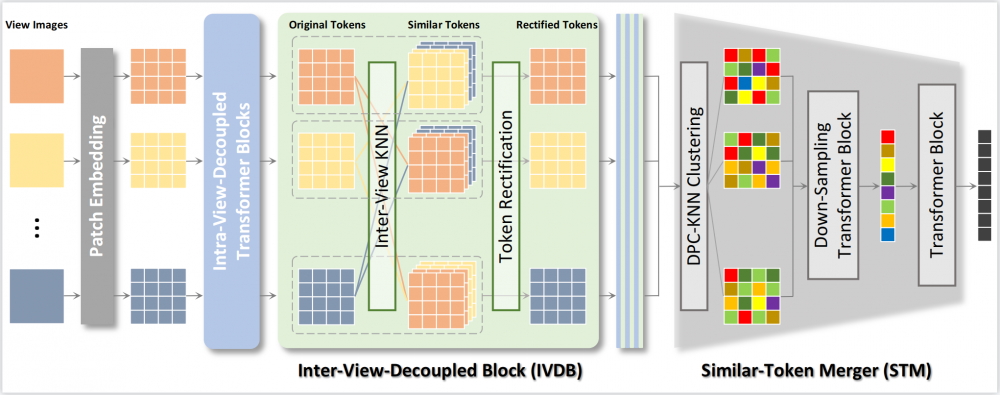
Figure 2. The pipeline of our proposed method.
2. Sign Language Translation (SLT) is a challenging task due to its cross-domain nature, involving the translation of visual-gestural language to text. Many previous methods employ an intermediate representation, i.e., gloss sequences, to facilitate SLT, thus transforming it into a two-stage task of sign language recognition (SLR) followed by sign language translation (SLT). However, the scarcity of gloss-annotated sign language data, combined with the information bottleneck in the mid-level gloss representation, has hindered the further development of the SLT task. To address this challenge, we propose a novel Gloss-Free SLTbase on Visual-Language Pretraining (GFSLT-VLP), which improves SLT by inheriting language-oriented prior knowledge from pre-trained models, without any gloss annotation assistance. Our approach involves two stages: (i) integrating Contrastive Language-Image Pre-training (CLIP) with masked self-supervised learning to create pre-tasks that bridge the semantic gap between visual and textual representations and restore masked sentences, and (ii) constructing an end-to-end architecture with an encoder-decoder-like structure that inherits the parameters of the pre-trained Visual Encoder and Text Decoder from the first stage. The seamless combination of these novel designs forms a robust sign language representation and significantly improves gloss-free sign language translation. In particular, we have achieved unprecedented improvements in terms of BLEU-4 score on the PHOENIX14T dataset (+6) and the CSL-Daily dataset (+3) compared to state-of-the-art gloss-free SLT methods. Furthermore, our approach also achieves competitive results on the PHOENIX14T dataset when compared with most of the gloss-based methods.
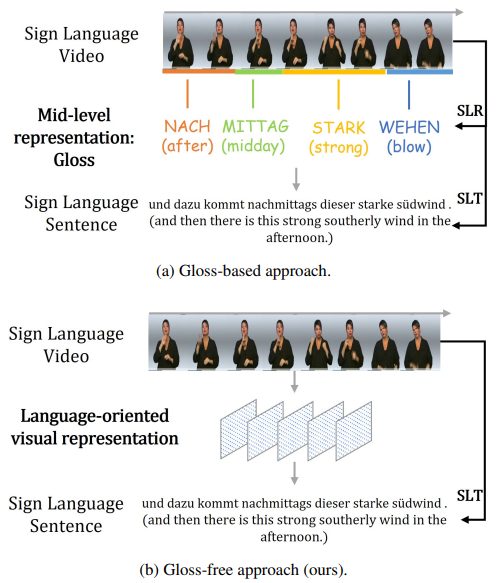
Figure 1. Two SLT approaches: (a) using gloss sequences as intermediate representations, e.g., Sign2Gloss2Text (directly), Sign2Text (indirectly), (b) not using gloss info throughout the training/inference process.
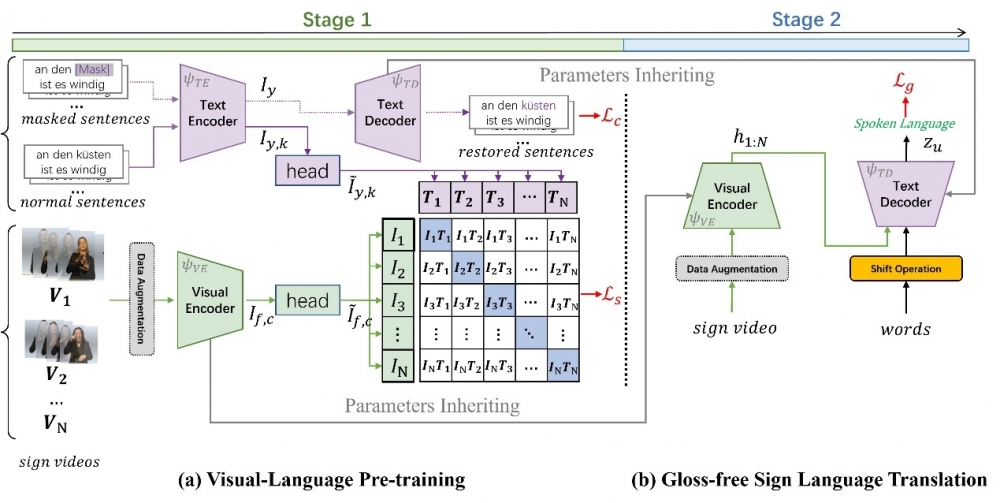
Figure 2. The pipeline of our proposed method. We improve the SLT by (a) performing Visual-Language Pretraining in the first stage, and then (b) inheriting parameters of the pre-trained Visual Encoder and Textual Decoder in the second stage.
3. Nowadays, transformer networks have demonstrated superior performance in many computer vision tasks. In a multi-view 3D reconstruction algorithm following this paradigm, self-attention processing has to deal with intricate image tokens including massive information when facing heavy amounts of view input. The curse of information content leads to the extreme difficulty of model learning. To alleviate this problem, recent methods compress the token number representing each view or discard the attention operations between the tokens from different views. Obviously, they give a negative impact on performance. Therefore, we propose long-range grouping attention (LGA) based on the divide-and-conquer principle. Tokens from all views are grouped for separate attention operations. The tokens in each group are sampled from all views and can provide macro representation for the resided view. The richness of feature learning is guaranteed by the diversity among different groups. An effective and efficient encoder can be established which connects inter-view features using LGA and extract intra-view features using the standard self-attention layer. Moreover, a novel progressive upsampling decoder is also designed for voxel generation with relatively high resolution. Hinging on the above, we construct a powerful transformer-based network, called LRGT. Experimental results on ShapeNet verify our method achieves SOTA accuracy in multi-view reconstruction.
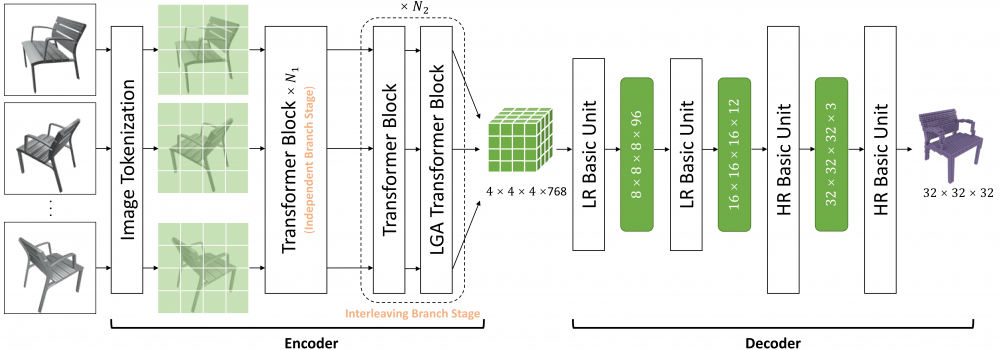
Figure 1. The pipeline of our proposed method.