第19屆國際計算機視覺會議(International Conference on Computer Vision (ICCV) 2023)於7月14日公布了論文接收情況,創新工程學院計算機科學與工程學院的多篇論文獲接收。ICCV是最頂尖的人工智能與計算機視覺方向的國際會議之一(另一個為同是IEEE/CVF組織的國際會議The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)。ICCV每2年召開一次,今年將於10月2-6日在法國巴黎舉辦。
創新工程學院計算機科學與工程學院梁延研副教授、萬軍特聘副教授、張渡講座教授團隊今年在ICCV2023上投稿了7篇論文,其中3篇獲接收,三篇論文的第一作者分別為朱震威(三年級博士生)、楊儷瑩(二年級碩士生)和周本加(二年級博士生),通訊作者分別為梁延研副教授和萬軍副教授。作為第一作者的三位學生均為澳門科技大學本校培養的學生,其中,朱震威為2014級理學學士(軟件工程),2018級理學碩士(資訊科技),2020級人工智能博士在讀;楊儷瑩為2017級理學學士(電子資訊科技),2021級應用數學與數據科學碩士在讀,並即將入讀2023級理學博士(計算機技術及其應用);周本加為2019級理學碩士(資訊科技),2021級人工智能博士在讀。這是近年來澳門科技大學在計算機科學和人工智能相關學科方面關於培養人才和科學研究的重要成果。
這是繼在多個人工智能國際頂尖會議AAAI 2021、IJCAI 2022、CVPR 2022和AAAI 2023發表論文後,科研團隊在人工智能國際頂尖會議上取得的又一新突破,也是澳門科技大學作為第一單位首次於ICCV發表研究論文。上述會議均得到中國計算機學會推薦並評級為人工智能領域的A類會議(注:A類為最高級別,中國計算機學會對該類別的定義是國際上極少數的頂級刊物和會議,鼓勵我國學者去突破)。
研究論文得到國家科技部-澳門科技發展基金聯合項目“通用視覺模型關鍵技術研究”(0070/2020/AMJ)、澳門科技發展基金面上項目“增強現實中的關鍵技術研究”(0004/2020/A1)和廣東省重點領域研發計劃項目“虛擬現實核心引擎關鍵技術平臺研發及産業化”(2019B010148001)資助。
三篇論文的題目和摘要簡介如下:
1. UMIFormer: Mining the Correlations between Similar Tokens for Multi-View 3D Reconstruction.
近年來,Vision Transformer結合空間-時間解耦的特征提取方法在視頻處理任務上取得突破。同樣作為應對多張圖像輸入的問題,多視角3D重建任務卻無法直接繼承這種方式。這是因為無序的視角之間關聯性完全不確定,並沒有類似於視頻數據中時序相關性的先驗條件可用。為了解決這樣的問題,我們提出了UMIFormer——一個全新的transformer網絡用於處理無序的多張圖像輸入。該結構利用Transformer塊做解耦的視圖內編碼,並依賴我們設計的token校正塊,挖掘不同視角之間相似tokens的關聯性,以實現解耦的視角間編碼。之後,再次依據相似性,將從各個視角分支獲取的tokens壓縮為固定大小的緊致表示,同時保留豐富的信息用於重建。在ShapeNet數據集上,我們驗證了所提出的解耦學習方式確實適用於處理無序的多張圖像。同時,我們的模型也大幅優於現有的最好方法。
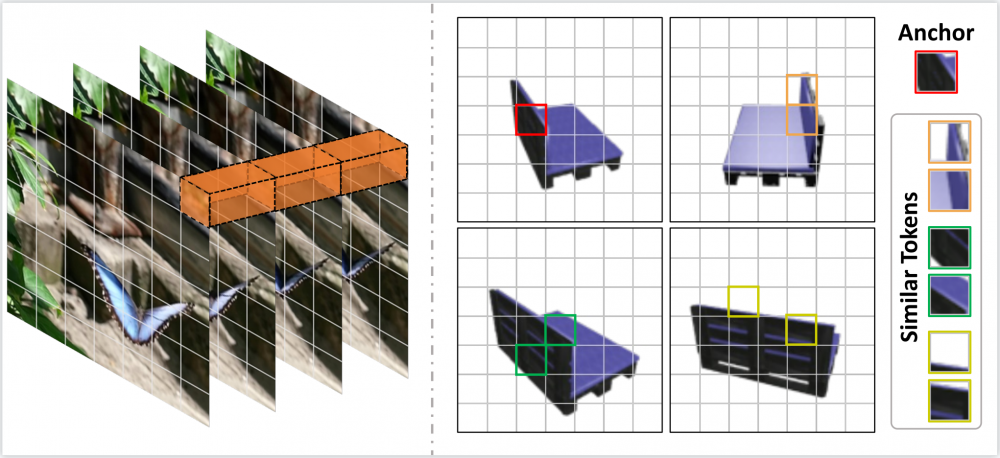
圖1. 多視角輸入的相似性Token示意圖,挖掘相似的Token有利於將相似信息形成關聯。
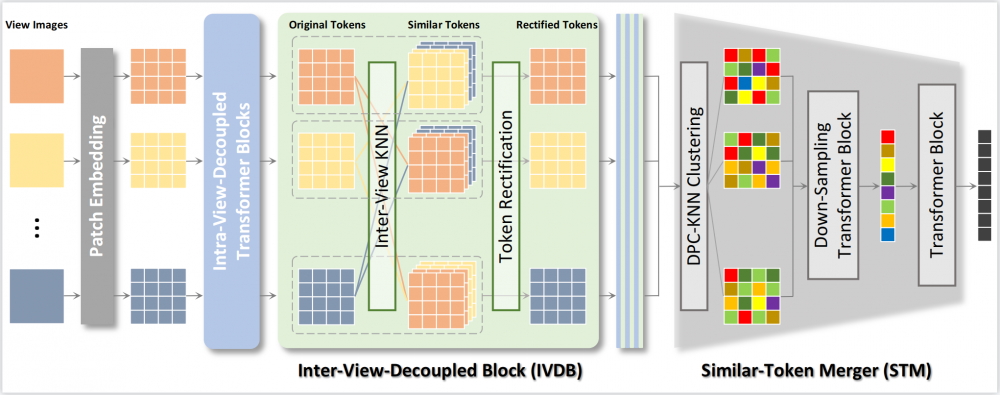
圖2. 所提出的方法架構。
2. Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining.
這篇文章中我們提出了一種不需要依賴Gloss 標注信息(gloss-free)的手語翻譯(SLT)方法: GFSLT-VLP。Sign Language Gloss 信息的標注需要花費巨大的人力物力成本,而且還需要專門的語言專家進行細粒度標注。這導致當數據規模比較大時,這種標注浪費資源且工程巨大。本文提出的Gloss-free SLT方法首次實現了在完全不需要依賴Gloss標注的情境下,顯著縮小了與Gloss-based 方法之間的性能差距。整個方法包含兩個關鍵步驟:(i)將多模態預訓練領域的視文對比學習範式(CLIP)和NLP領域的掩碼自監督學習範式(MSL)結合到一起預訓練視覺編碼器(Visual Encoder)和文本解碼器(Text Decoder)。(ii)構建一個端到端的SLT模型架構,它具有類似編碼器-解碼器的結構,並繼承了第一階段學習到的視-文知識,從而有效地捕獲到語言知識引導的手勢特征。這些新穎設計的無縫結合形成了魯棒的手語表示,並顯著提高了Gloss-free手語翻譯的性能。
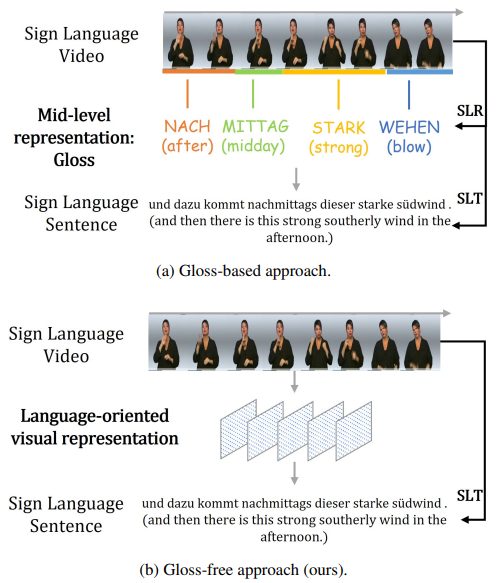
圖 1. 兩種不同的SLT方法。 (a)使用Gloss序列作為中間表示,例如,sign2gloss2text(直接),Sign2Text(間接);(b)在整個訓練/推理過程中不使用Gloss信息。
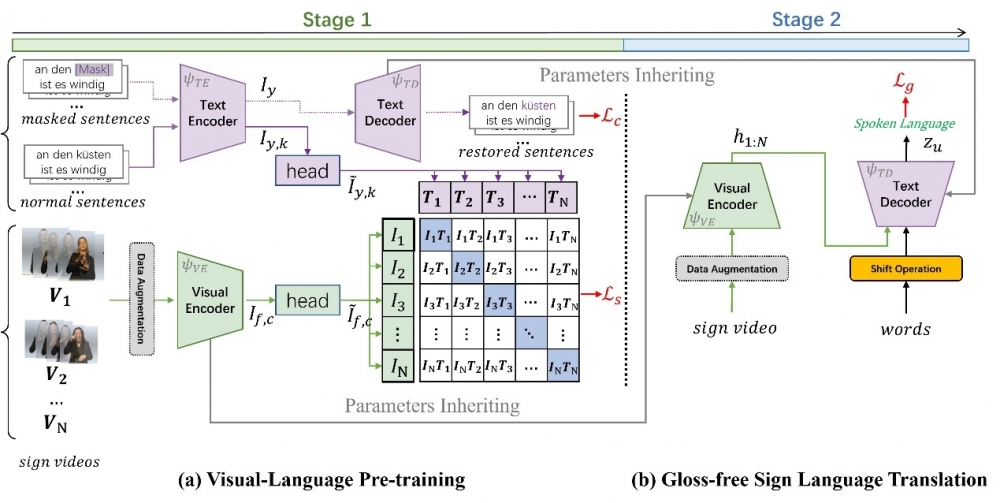
圖2. 所提出的方法架構。(a)第一階段進行視-文預訓練; (b)繼承視-文知識並進行端到端的手語翻譯任務。
3. Long-Range Grouping Transformer for Multi-View 3D Reconstruction.
目前,Transformer在許多計算機視覺任務中都表現出了優越的性能。在遵循這一範式的多視圖三維重建算法中,當面對大量的視圖輸入時,自注意力需要處理包含大量信息的複雜圖像令牌。信息內容的爆炸導致模型學習的難度極大。為了緩解這個問題,最近的方法壓縮了表示每個視圖的令牌,或者放棄計算不同視圖令牌之間的注意力。顯然,它們會對性能產生負面的影響。因此,我們提出了基於分而治之原則的長距離分組注意力(LGA)。來自所有視圖的令牌都會被分組,以進行單獨的注意力操作。每個組中的令牌從所有視圖中采樣,並且可以為當前視圖提供宏觀表示。不同組間的多樣性確保了特征學習的豐富性。我們通過使用LGA連接視圖間特征,並使用標准的自注意力層提取視圖內特征,提出一種高效的編碼器。 此外,我們設計出一個新穎的漸進式上采樣解碼器,用於生成具有相對高分辨率的體素。基於以上內容,我們最終構建出一種基於Transformer的網絡,命名為LRGT。在ShapeNet數據集上的結果證明LRGT在多視圖三維重建任務中達到了卓越的性能。
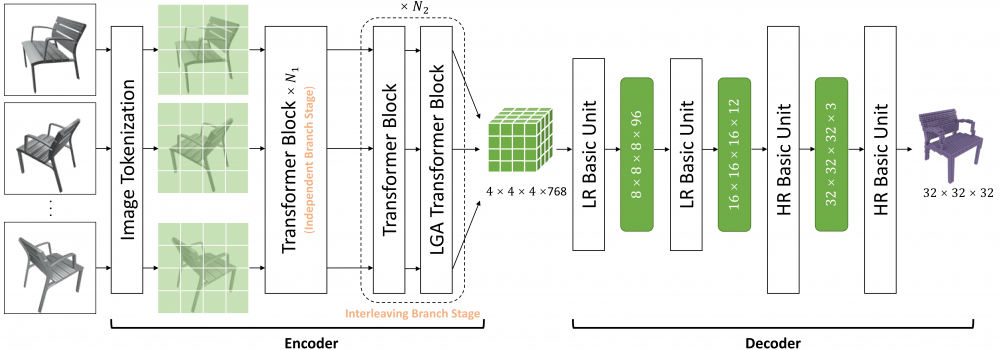
圖1. 提出的方法架構。